GPT-4o vs. Gemini vs. Claude 3.5 Sonnet on Image Recognition
I compared 3 LLMs on image recognition: GPT-4o, Gemini, and Claude 3.5 Sonnet. I gave each model a picture of my bookshelf and asked them to identify the books. Here’s an overview of the results:
📚 Books identified: How many books of the 20 shown did it correctly identify?
✅ Correct Guesses: How many books did it correctly guess
❌ Incorrect Guesses: How many books did it guess incorrectly
🧐 Attention Score: How many books did it identify in a row before it started hallucinating
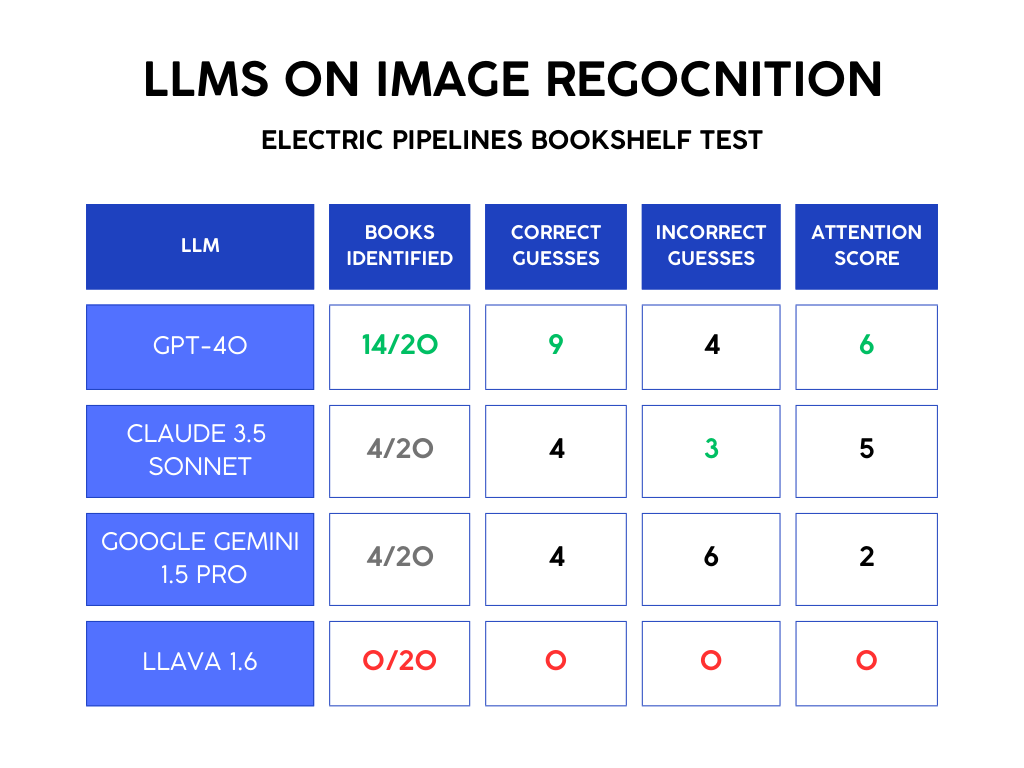
It’s useful to track correct and incorrect guesses because some models are bolder than others, and some are more OK with hallucinating. For example, Llava gets zeros across the board because it refused to guess. It wanted a higher-quality photo.
Detailed Results
ChatGPT:

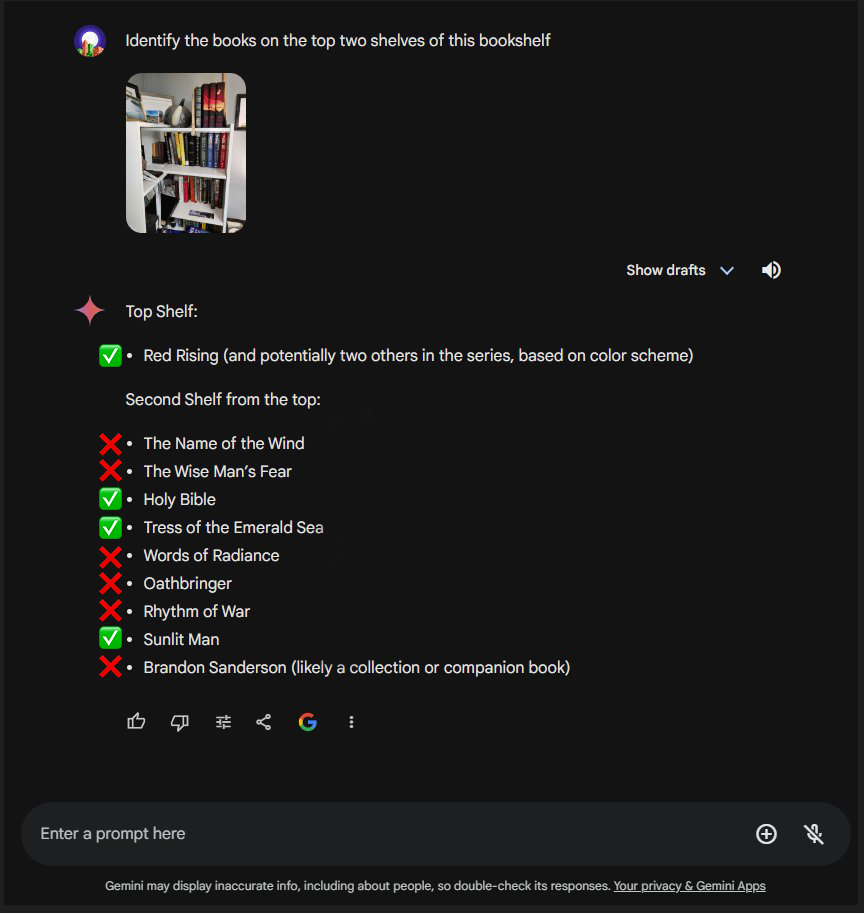
Gemini:
Claude:
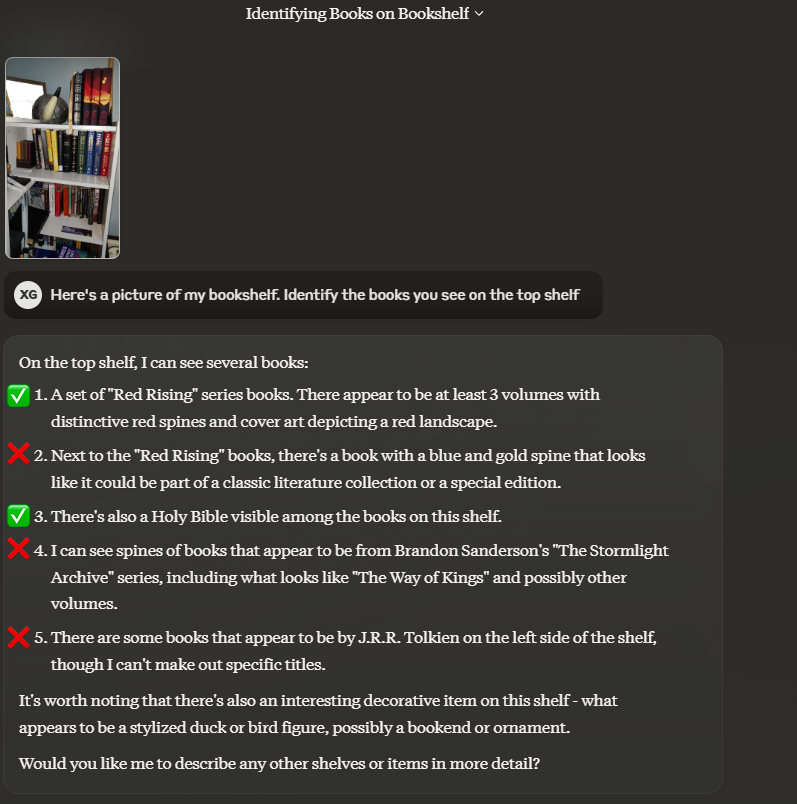
In general, Claude 3.5 seems very powerful. I think Claude 3 Sonnet was already equivalent with GPT-4o, but I don’t think y’all are ready for that conversation. It seems behind on vision, though.
Gemini did not do well here, but it did perform very well in a separate test where I used video. Still waiting on other models to support video.
Recent Posts
Using RAG and Ollama to Make a Health Bot
I used RAG to make a medical diagnosis bot that uses med school textbooks to answer questions. These are the 4 steps I took.
AI Used a Video of My Fridge to Fix My Diet
I used Google Gemini and Dabarqus, our no-code RAG app to take a video of my fridge and my diet from MyFitnessPal to find recipes that fill holes in my diet with foods I already have. This is how it went.
Comparing AI Image Recognition
I compared 3 LLMs on image recognition: GPT-4o, Gemini, and Claude 3.5 Sonnet. I gave each model a picture of my bookshelf and asked them to identify the books. Here’s the results:
Using AI for Medical Report Analysis
I used Google Gemini, Langchain and Llama 3 to turn a medical report into an action plan for a patient. I couldn’t believe how good of a job they did, and it only took me one hour. This is how I did it.