Teaching AI to Memorize My Documents
The major challenge in AI right now has nothing to do with intelligence.
We have plenty of AIs that are plenty smart (even if sometimes they don’t seem like it).
Even that issue with Google has nothing to do with how smart their AI is. AIs are passing the BAR exam, and they’re scoring high enough to get into med school, and they’re still telling you that you should eat one rock per day.
The major challenge in AI right now is how to give an AI concrete, real-world information. Today, we’ll be talking about what makes giving AI real information hard and the solutions we’ve found at Electric Pipelines through our research.
What Are We Trying to Do?
For any of this to make sense, we have to talk about our target outcome. We are making an AI that knows about you and your business. In particular, we’re building an AI that can read your documents and that can improve itself over time. That’s all fine and good, but an AI can’t read your documents out of the box. To get an AI to understand documents, you have to use something called Retrieval Augmented Generation, or RAG.
I know, it’s not a good name.
RAG (and why it matters)
RAG gives AI the ability to go look things up while it’s answering a prompt. That could mean looking at some Word docs, it could mean checking your email, or even searching Google. If you need AI to access something in the outside world, it needs RAG. Otherwise, it only knows what it was trained on. This is how Google’s AI works, and how ChatGPT can generate images. There are a lot of different things that RAG can do, but to read documents, we use Vectorization.
It’s gonna be a lot more understandable if we use a concrete example. We’re going to use a PDF of the play Hamlet (don’t worry, I didn’t steal it!). That way we can look at text with some variety of formatting and of a decent length.

The most basic way we could get this to the AI would be to copy and paste the whole document into a prompt.
This is super inefficient, and it just doesn’t work if you have multiple documents or if your document is too long. So, in order to have an AI understand this document, we have to vectorize it.
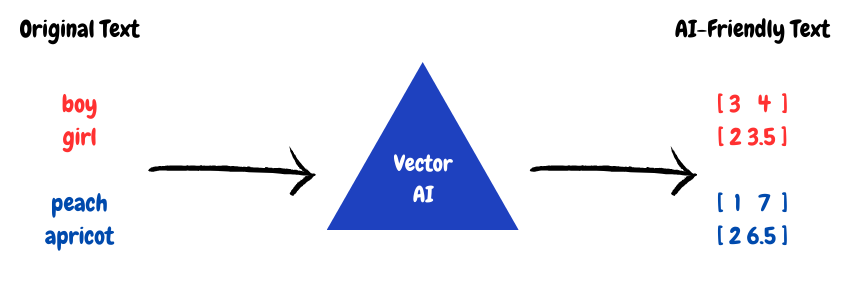
That means we have to turn it into a bunch of numbers. This is how an AI can get the meaning of the document instead of having the specific words. It’s really easy to make an app that can search a document for a specific word. It’s built in to all of our document apps.
What we want is the power of AI to understand meaning, like a person does. If we use Vectorization, we can turn a document into something an AI can actually work with. That’s only one part of the problem, though.
Chunking
The problem we keep coming back to is the context window. The AI can only consider a certain amount of text at a time. AI can only store a certain number of tokens (just think of it as words) in their memory before they have to start forgetting old stuff.

Even models with “near infinite” context don’t perform like it. Google Gemini has 1M token context, so it can hold entire books in context at one time. It’s ok at searching for very specific things, but it can’t reason on the whole set at one time.
So, even if we manage to turn all of our documents into a nice set of numbers, only some of them can be understood by the AI at any given point.
We get around this by breaking our documents up into smaller pieces that the AI can understand. Or smaller chunks. Cause we call it chunking.
So, let’s apply chunking to our document example. This is what the first version of Dabarqus did.

But, then we run into a new problem: where do we decide to make the chunks? We could chunk it by page, but that wouldn’t be good here. We want the AI to be able to summarize each chunk. And the first page ends partway through a paragraph.
We could instead chunk it by paragraph:

This is just bad from two angles.
First, there’s not going to be enough greater context here. This would be great if you needed to just look up where quotes are, but if you want something more powerful, like being able to actually reason about the text, you’ll need a larger chunk.
Second, we end up with paragraphs that are only a couple sentences long. And the more chunks, the slower and less useful it is for the AI. We have to do better.
Instead, Dabarqus uses a dynamic chunking system that looks at the document’s composition and uses that to generate more meaningful chunks:

Putting It All Together
We’ll end with a real example of Dabarqus at work. It’s a command line tool, but here’s a peek at what it looks like to store a few documents at a time.
We dynamically chunk documents into pieces that can then be vectorized so the AI can understand them. In simpler terms, Dabarqus allows you to store documents in a memory bank so that AI can use them as if they’re all in context.
Like I said earlier, Dabarqus is the tech powering ODOBO, our AI assistant. You can sign up to hear about access as soon as that app launches at the form below.
If the Dabarqus tech sounds useful to your business, contact us today and we can talk about how Electric Pipelines can set up a Dabarqus inside your company.
Soon, we’ll talk about how the rest of the tech works, like retrieval, and the self-improvement portion of Dabarqus. Until then!
Want to know as soon as ODOBO is ready for download?
Recent Posts
Using RAG and Ollama to Make a Health Bot
I used RAG to make a medical diagnosis bot that uses med school textbooks to answer questions. These are the 4 steps I took.
AI Used a Video of My Fridge to Fix My Diet
I used Google Gemini and Dabarqus, our no-code RAG app to take a video of my fridge and my diet from MyFitnessPal to find recipes that fill holes in my diet with foods I already have. This is how it went.
Comparing AI Image Recognition
I compared 3 LLMs on image recognition: GPT-4o, Gemini, and Claude 3.5 Sonnet. I gave each model a picture of my bookshelf and asked them to identify the books. Here’s the results:
Using AI for Medical Report Analysis
I used Google Gemini, Langchain and Llama 3 to turn a medical report into an action plan for a patient. I couldn’t believe how good of a job they did, and it only took me one hour. This is how I did it.